How to Use Change Data Tracking
- 5 Minutes to read
- Print
- DarkLight
- PDF
How to Use Change Data Tracking
- 5 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback
Change Data Tracking is an optional feature that marks leaf-level data as dirty whenever it is changed, such as through user input, calculations, or data load. When the next full aggregation (Aggregation, None) is performed, only the rollups with dirty leaf-level data are aggregated. This makes full aggregations faster.
Enabling Change Data Tracking is helpful in cases where users are updating one or two departments’ data and need to run a full aggregation to see the data rolled up against all departments. Once Change Data Tracking is enabled, the application will track which data blocks are changing. When a full aggregation is run, instead of running the aggregation for the entire model, the system will run aggregation only for the blocks that changed (in this case, the departments that changed and the dependent rollup members), so the total aggregation process will take less time.
Change Data Tracking is available for all applications, but it is turned off by default for each model. You must turn this feature on for models that will use Change Data Tracking.
Here are the overall steps to use Change Data Tracking.
- Select a model.
- Run a full aggregation (Aggregation, None) on the model. This ensures that data is clean to begin with.
- Turn on Change Data Tracking for the model. Thereafter the feature works seamlessly.
- Whenever you aggregate going forward, do a full aggregation to get the full benefit of this feature.
How It Works
This feature tracks changes to the data blocks; that is, it marks leaf-level data as dirty whenever it changes. The changes may be due to actions such as saving data entries, running a calculation, or loading data from an external source.
When a full aggregation is run, it aggregates only those blocks that have changed. (Blocks are formed from the dimension intersections of all Value dimensions in the model.) If few changes have been made since the last full aggregation, it will run faster. Once the aggregation is completed, all the dirty flags are cleared and the data is assumed to be clean again.
Enabling Change Data Tracking
Either a Power User or a Contributor can enable Change Data Tracking for a particular model.
- Login to the model. The model must be of type Master or Analytic.
- Ensure that no calculations are running on the model and that there are no active users or processes that are modifying data.
- Run a full aggregation (Aggregation, None) before the feature is turned on. Wait for the aggregation to be completed before continuing. Failure to complete this step will result in incorrect rollup values.
- Go to Model > Setup.
- Select the model from the Model list box.
- You will see a new item, Enable Change Data Tracking. Select Yes.
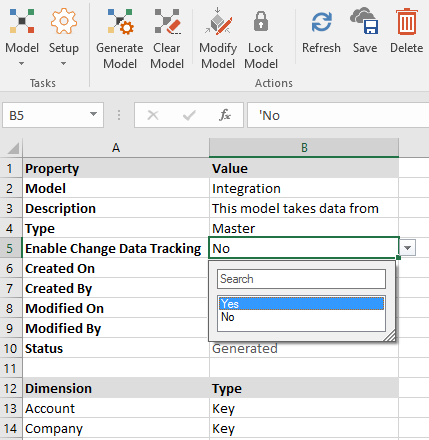
- Click Save.
If, in the future, you decide that you do not want to use Change Data Tracking, you can set Enable Change Data Tracking to No for the model.
Aggregation with and without Scope
Change Data Tracking is intended to be used with full aggregations, that is, aggregations without scope (Aggregation, None). A full aggregation looks at all blocks to determine which blocks contain dirty data, and it aggregates those blocks and the dependent rollup blocks that need to be aggregated due to changes in the leaf-level data. Blocks without dirty data are skipped. After a full aggregation is completed, all the dirty flags are cleared.
You may have existing defined calculations that contain aggregations with scope. These aggregations ran faster in the past than full aggregations because they limited the number of blocks that would be calculated. For example, Aggregation, and BudgetScope. If you run an aggregation with the scope with Change Data Tracking Enabled, Dynamic Planning looks at the blocks within the scope to determine which blocks contain dirty data, and it aggregates those blocks. Blocks without dirty data are skipped. However, the dirty flags are not cleared after the scoped aggregation.
Best Practice
Perform full aggregations regularly. Because this feature performs optimized aggregations based on tracked changes to leaf data, it is best to aggregate regularly so the amount of dirty data stays within reason. If you never run a full aggregation, the aggregation performance will deteriorate with time. That is, it will become closer and closer to a full non-optimized aggregation over time. Additionally, scoped aggregations do not clear the dirty flag. Therefore, we recommend performing full aggregations regularly or completely switching to using full aggregations instead of scoped aggregations whenever you need to aggregate.
Calculations with ClearRollupData
If you run a calculation containing the command ClearRollupData on a model, Change Data Tracking is effectively turned off temporarily for that model. Because all affected rollups and potentially their leaf members (if MemberAndBelow is used) are cleared, Dynamic Planning assumes that all rollups need to be aggregated again. Therefore, the next aggregation will not be optimized. Change Data Tracking will resume after the next full aggregation.
Calculations with ClearLeafData
If you run a calculation containing the command ClearLeafData on a model, all affected blocks are marked as dirty in that model.
Note:
In coming releases, this functionality may be optimized so that blocks are only marked as dirty if they changed. Since ClearLeafData marks data as 0, some existing leaf data may have already been 0. However, in this release, all cleared leaf data is assumed to be dirty.
Backup and Restore
When you run a Backup process, dirty flags are not included in the backup and the fact that Enable Change Data Tracking was set to Yes is not backed up. When you restore a model from backup, the model will have Enable Change Data Tracking set to No by default. You will need to do a full aggregation and then re-enable the feature in the restored model.
Pausing Change Data Tracking
The following actions have the effect of turning Change Data Tracking off temporarily.
- Running ClearRollupData on a model
- Updating the hierarchy when the model is locked
- Using APIs with Dynamic Planning, model, clear, and data
Change Data Tracking will resume after the next full aggregation.
Forcing a Full Non-Optimized Aggregation
If you want to run a full aggregation of all blocks in the model, here is the best practice:
- Run a calculation containing ClearRollupData. Wait for the calculation to be completed before continuing.
- Run a full aggregation.
Change Data Tracking Impact
Operations that mark leaf-level data as dirty:
- A user changes leaf-level data and saves it from a view or report
- A calculation changes leaf-level data with a formula
- Leaf-level data is changed from running a map
- Leaf-level data is changed from a data load from the API or Data Load screen
- Leaf-level data is changed in a Master model from data from HACPM
- Leaf-level data is changed from a data load from an external source model
- Leaf-level data is changed from an import
Operations that clear all dirty flags:
- Running a full aggregation
- Running a calculation containing ClearAllData on a model
- Running a calculation containing ClearModel on a model
Operations that mark all affected data as dirty:
- Running a calculation containing ClearLeafData on a model
Operations that pause Change Data Tracking and force the next aggregation to be a full aggregation:
- Running a calculation containing ClearRollupData on a model
- Updating the hierarchy
Operations that turn off Change Data Tracking:
- Restore from backup
HACPM
HACPM is a special model that takes metadata and data from Planful Applications and then acts as a source for moving that data into a Dynamic Planning model. Enable Change Data Tracking is not available on HACPM.
Was this article helpful?